
Large language models (LLMs) have come a long way from being mere research curiosities to becoming essential tools that help businesses turn simple prompts into fully functional applications. By 2026, companies in sectors like ecommerce, healthcare, finance, and customer service will be creating LLM powered apps that generate billions in value. This transition from just prompt engineering to scalable products takes advantage of fine tuning, retrieval augmented generation (RAG), agentic workflows, and API orchestration. Keywords such as LLM app development, building apps on LLMs, and RAG implementation are trending in SEO, reflecting the growing interest in LLM business applications. This comprehensive guide breaks down the architecture’s real world applications, monetization strategies, challenges, and future directions.
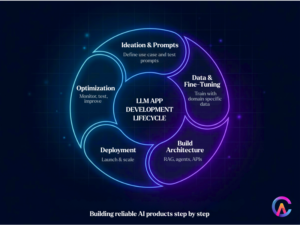
The LLM App Development Lifecycle
Creating production ready LLM apps involves a structured approach that balances speed, reliability, and cost.
Ideation and Prompt Engineering Foundations
Begin with MVP prompts to test the core value. For instance, ecommerce chatbots have evolved from simply “recommending products” to offering context aware personalization that takes into account user history, inventory, and pricing. Through iterative refinement and A/B testing on platforms like LangSmith, businesses can see accuracy improvements of 30-50%.
Companies also map out user journeys to define intents such as query resolution, troubleshooting, or upselling. Persona based prompts help tailor the tone, ensuring B2B communications are formal while consumer interactions feel friendly.
Data Preparation and Fine Tuning
Raw prompts often fall short when scaled. Fine tuning adjusts base models like Llama 3.1 or Mistral using domain specific data, enhancing precision by 20-40%. Parameter efficient fine tuning methods, like LoRA, significantly reduce computing needs by up to 90%, making it accessible for small and medium sized businesses.
Generating synthetic data through self instruction allows for a variety of scenarios. Enterprises also build knowledge bases for RAG, incorporating proprietary documents through vector databases like Pinecone or Weaviate.
Core Architectures Powering LLM Apps
Technical patterns help streamline deployment.
Retrieval Augmented Generation (RAG) Systems
RAG pulls in relevant documents before generating a response, which helps avoid those pesky hallucinations. It uses a hybrid search that combines keyword and semantic ranking, and with advanced reranking through cross encoders, we see a 15% boost in precision.
Chunking strategies break documents into 512 token overlaps, ensuring that context is preserved. ColBERT embeddings are great for capturing detailed matches, making them perfect for applications in legal or medical fields.
Agentic Workflows and Tool Calling
Agents break down tasks into manageable steps, coordinating with APIs, databases, or other external tools. OpenAI’s Assistants API or LangGraph can facilitate multi step reasoning, like “analyze sales data and then draft a report.”
ReAct prompting creates a loop of reasoning, acting, and observing, which refines outputs on the fly. Guardrails are in place to validate tool calls, preventing errors such as invalid SQL queries.
Multimodal LLM Applications
Vision language models can handle images, text, and voice. GPT 4o powers visual search capabilities, allowing users to “find similar products in this photo.” Speech to text pipelines through Whisper help build voice assistants that can manage over 100 languages.
Industry Implementations and Case Studies
Businesses deploy across verticals.
Ecommerce Personalization Engines
Shopify apps are leveraging large language models (LLMs) to create dynamic product descriptions, boosting content creation speed by ten times. Recommendation systems are enhancing cross selling through engaging conversational flows, which have led to a 25% increase in average order value. Plus, search reranking has been shown to improve conversion rates by 18%, according to Algolia benchmarks.
Customer Support Automation
Zendesk is utilizing LLMs to handle 40% of support tickets through self service agents. Their sentiment analysis feature helps route escalations before they become issues. With multilingual support, they can scale their services globally without the need for additional hiring.
Enterprise Software copilots
Salesforce’s Einstein GPT is a game changer, drafting emails, summarizing meetings, and even predicting deal closures. Custom skills can be added easily through low code builders, leading to productivity gains of up to 30%, as reported by Forrester.
Healthcare Diagnostic Assistants
LLMs are being used to triage symptoms and suggest next steps, always with appropriate disclaimers. Med PaLM 2 has achieved an impressive 86% accuracy on USMLE questions, while retrieval augmented generation (RAG) pulls in the latest studies to ensure responses are evidence based. Financial applications are also stepping up, generating compliance reports from transaction logs and flagging anomalies in real time.

Monetization and Scaling Strategies
As production demands grow, sustainable economics become crucial.
Usage Based Pricing Models
Charging per token or conversation turn reflects the economics seen with OpenAI. Tiered plans can bundle queries with premium voices or custom models, similar to the credit systems used by Midjourney, which cap usage for heavy users.
Enterprise Licensing and White Labeling
SaaS platforms are licensing LLM stacks for branding purposes. Per seat pricing allows for scaling based on team size, while VPC deployments ensure data sovereignty through air gapped solutions.
Hybrid Human-AI Loops
Incorporating a human in the loop approach helps address edge cases, allowing for iterative model training. Revenue from premium support combines automation with human expertise. Cost optimization is achieved by distilling smaller models like Phi-3, which can match GPT-3.5 at just 10% of the inference cost, while caching frequent queries can reduce expenses by 50%.
Technical Challenges and Proven Solutions
Scaling can reveal some tricky pitfalls.
Hallucinations and Reliability
Using RAG grounding can cut down on inaccuracies by 70%. With Constitutional AI, we set clear response guidelines, like always citing sources. Plus, employing multi LLM voting ensembles helps boost our confidence in the results.
Latency and Cost at Scale
Asynchronous processing helps manage non urgent tasks efficiently. Speculative decoding can speed up inference by 2x. Deploying regional edge solutions through Cloudflare Workers helps keep latency to a minimum.
Security and Prompt Injection
We ensure input sanitization to eliminate harmful payloads. A tools only mode creates a safe environment for executions. Fine tuning for enterprises helps remove any sensitive information.
Evaluation Frameworks
When it comes to evaluation, we look beyond just accuracy. LLM as judge assesses fluency, coherence, and task completion. HELM benchmarks help standardize testing across different providers.
Deployment Infrastructure and Best Practices
We standardize our production stacks for consistency.
API Orchestration Layers
With tools like LangChain, Vercel AI SDK, or LlamaIndex, we can easily switch between providers. Observability is enhanced through Phoenix, which tracks latency, tokens, and errors.
Model Hosting Options
We can go serverless with AWS Bedrock or Azure OpenAI, which scale automatically. For self hosted vLLMs on Kubernetes, we optimize GPU usage up to 80%. Mixture of Experts (MoE) models, like Mixtral, efficiently route queries.
Monitoring and Iteration
Drift detection helps us spot any performance drops. A/B testing allows us to direct 10% of traffic to different variants. Continuous user feedback loops help us fine tune our approach.
As a case study, the Replicate platform hosts over 10,000 custom models, generating $50 million in annual recurring revenue through marketplace economics.
Future Trends in LLM Productization
2026 is set to turbocharge innovation.
Autonomous AI Agents
Imagine multi agent systems working together on intricate workflows. Think of Devin style coding agents that can deliver production software straight from specifications.
On Device Inference
Phi Slama operates locally, ensuring privacy while cutting costs. Federated learning brings together improvements without the need to centralize data.
Vertical Model Specialization
LLMs tailored for specific domains are outshining the generalists. For instance, BioMedGPT excels in medical Q&A, while LegalBERT crafts contracts with precision.
Open Source Dominance
Llama Grok and Mistral are making intelligence more accessible. We’re seeing the rise of fine tuning marketplaces, like Hugging Face Spaces, that are turning a profit.
According to Gartner, by 2028, 80% of new SaaS features will be powered by LLMs. The key to success will be mastering orchestration rather than just relying on raw model power.
How CodeAries Helps Customers Build LLM Powered Apps
CodeAries speeds up the journey of developing LLM apps from the initial idea to full scale production. Here’s how we turn your prompts into products that generate revenue:
- Design RAG pipelines that integrate knowledge bases for accurate and reliable responses.
- Build agentic workflows that seamlessly orchestrate APIs, databases, and external tools.
- Create multimodal applications that handle text, voice, and images for a richer user experience.
- Develop scalable deployment stacks with monitoring, cost optimization, and security in mind.
- Implement fine tuning pipelines to customize models for your specific domain data and use cases.
Frequently Asked Questions
Q1: What makes RAG essential for production LLM apps?
RAG helps ground responses in your data, which prevents those pesky hallucinations and allows for updates without the need for retraining.
Q2: How do agentic workflows differ from simple chatbots?
Agents take complex tasks and break them down into manageable steps, using tools and reasoning loops to tackle multi step problem solving.
Q3: Can businesses run LLMs without cloud dependency?
Absolutely, On device models and self hosted inference provide privacy, save costs, and ensure low latency.
Q4: How much does LLM app development typically cost?
Entry level MVPs start small and scale with usage, while enterprise solutions focus on tailored ROI metrics.
Q5: What industries benefit most from LLM apps?
E-commerce, healthcare, and finance are seeing the quickest ROI thanks to personalization, automation, and valuable insights.
For business inquiries or further information, please contact us at
